📝 Background
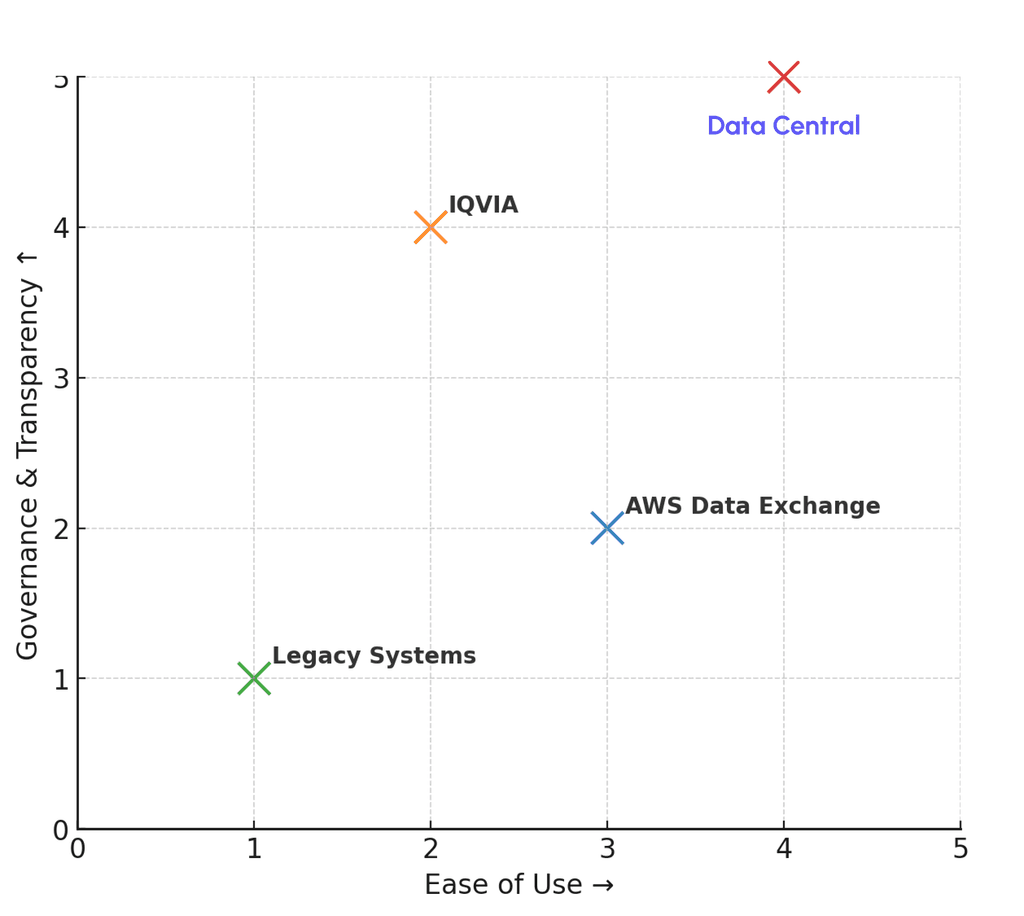
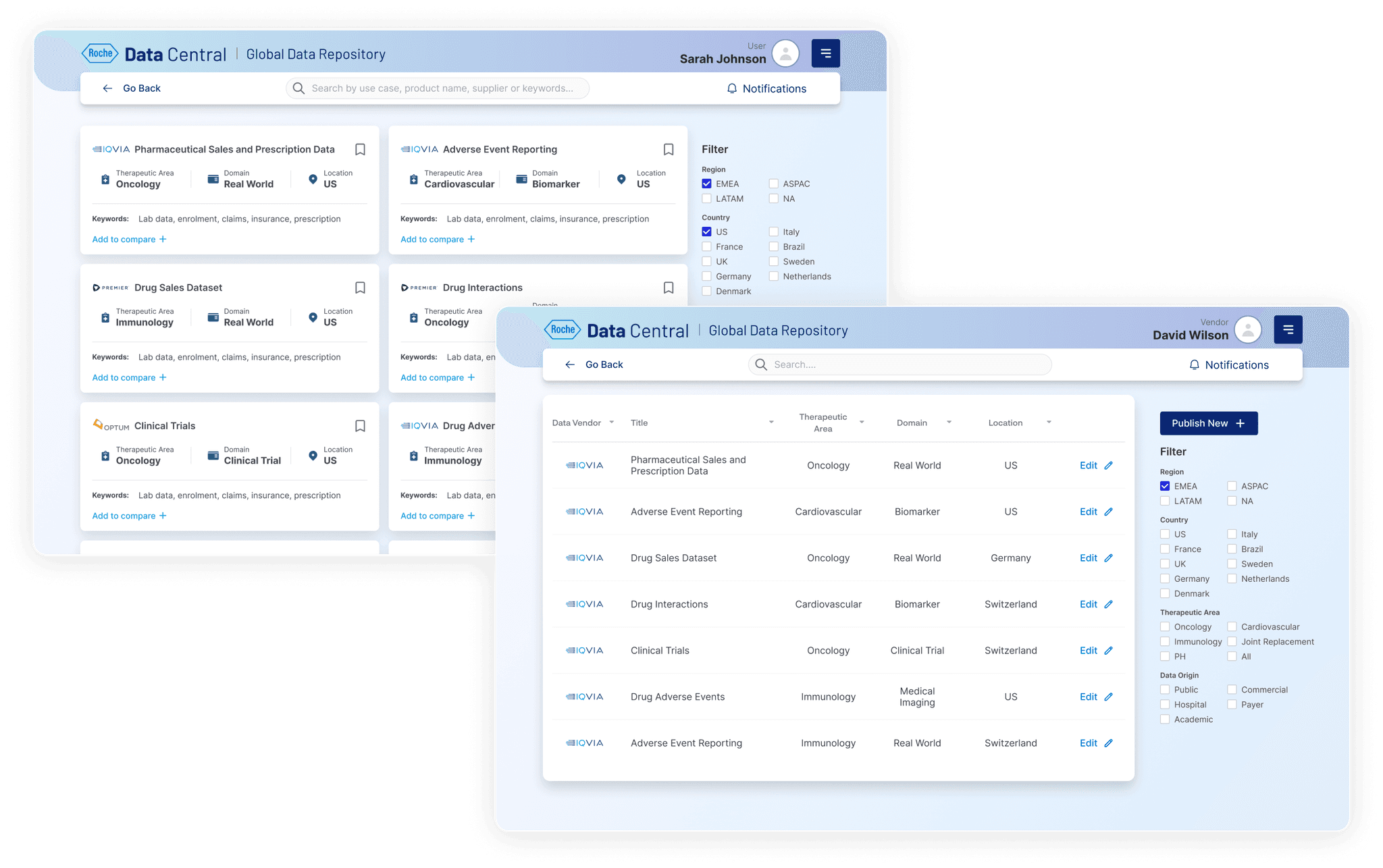
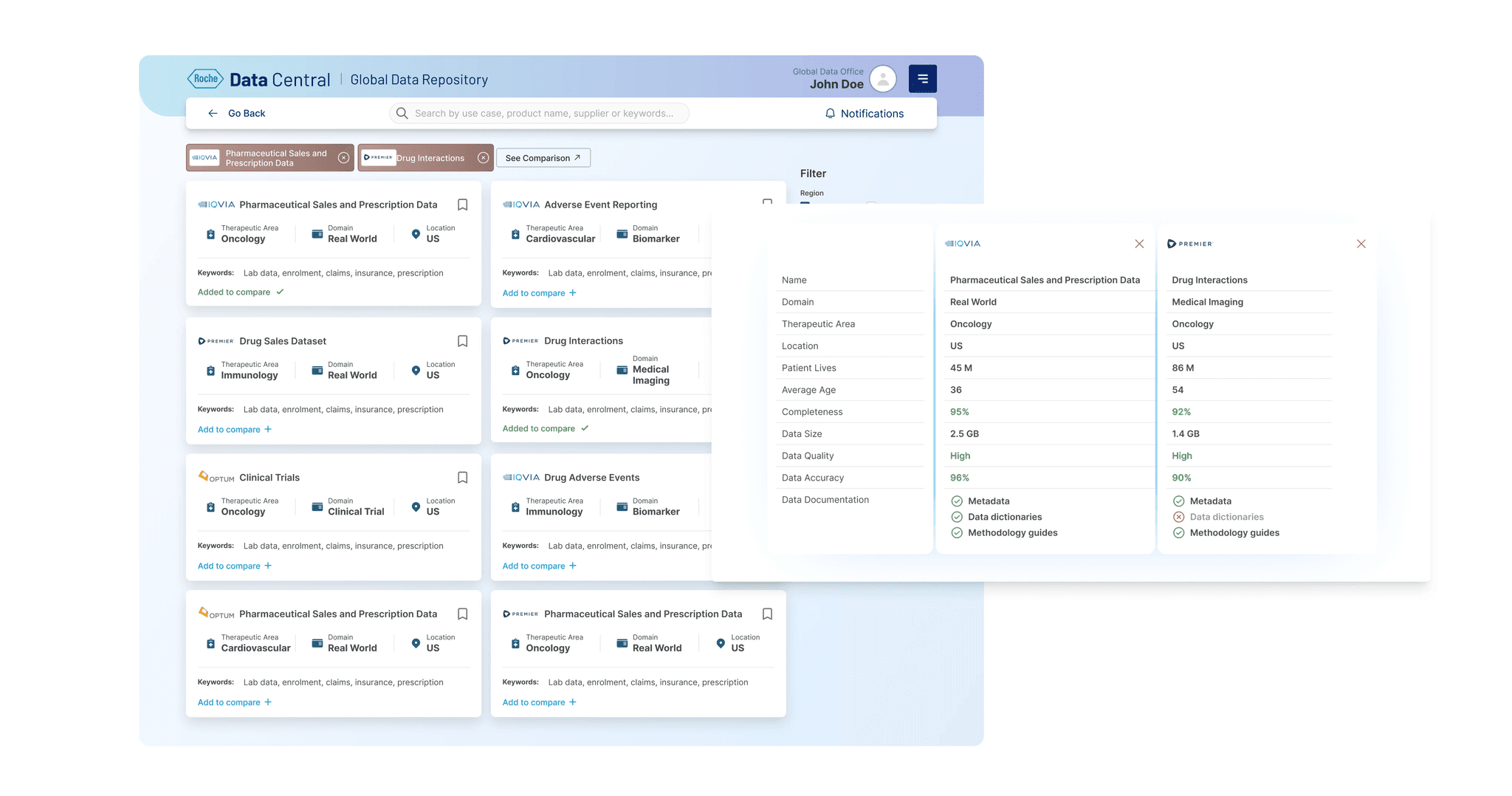
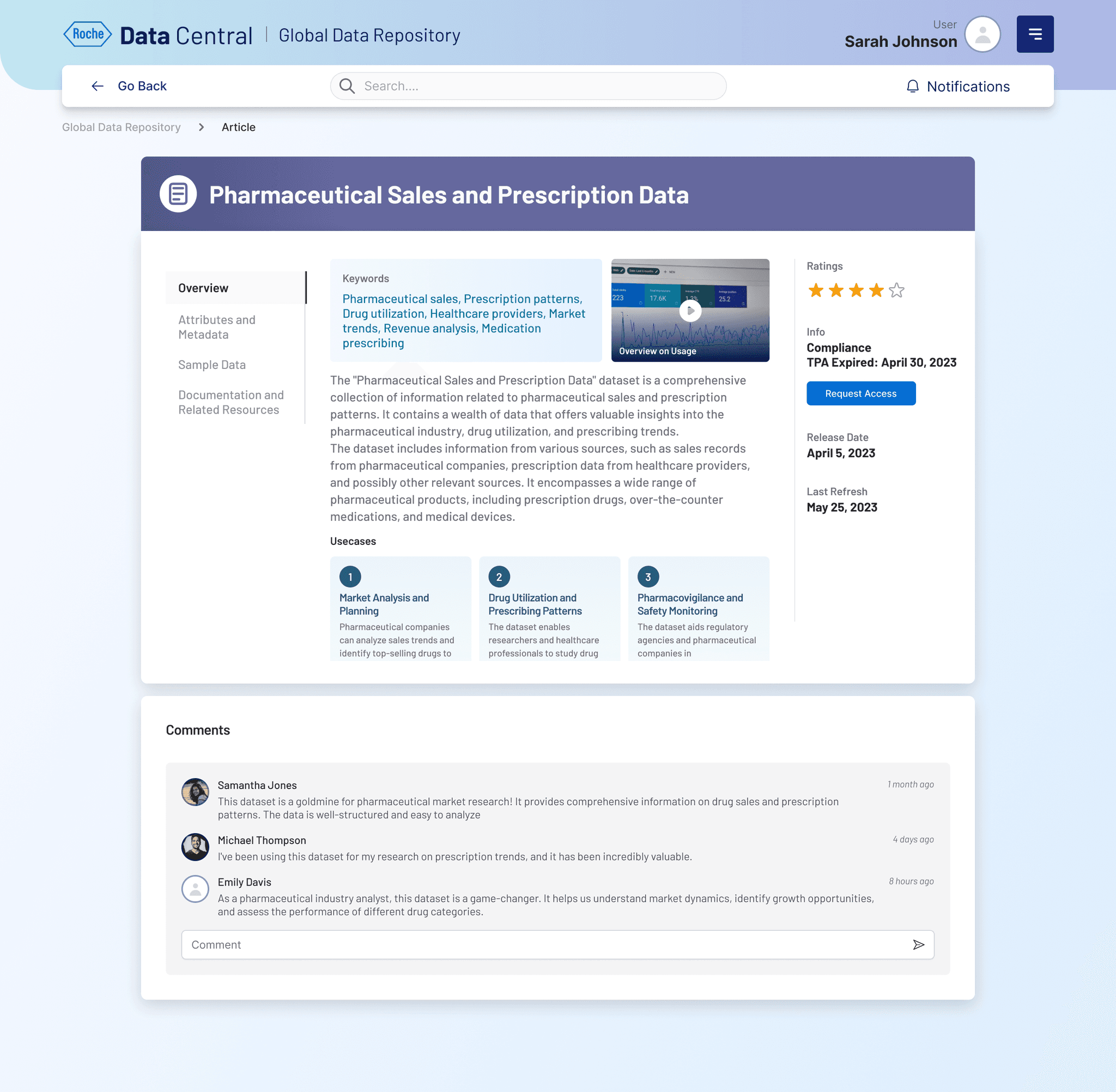
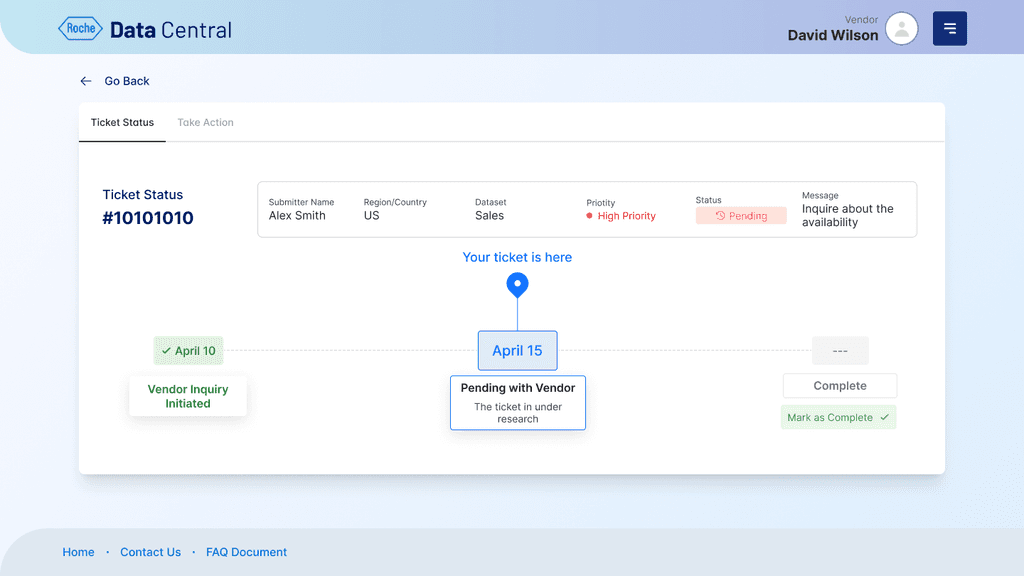
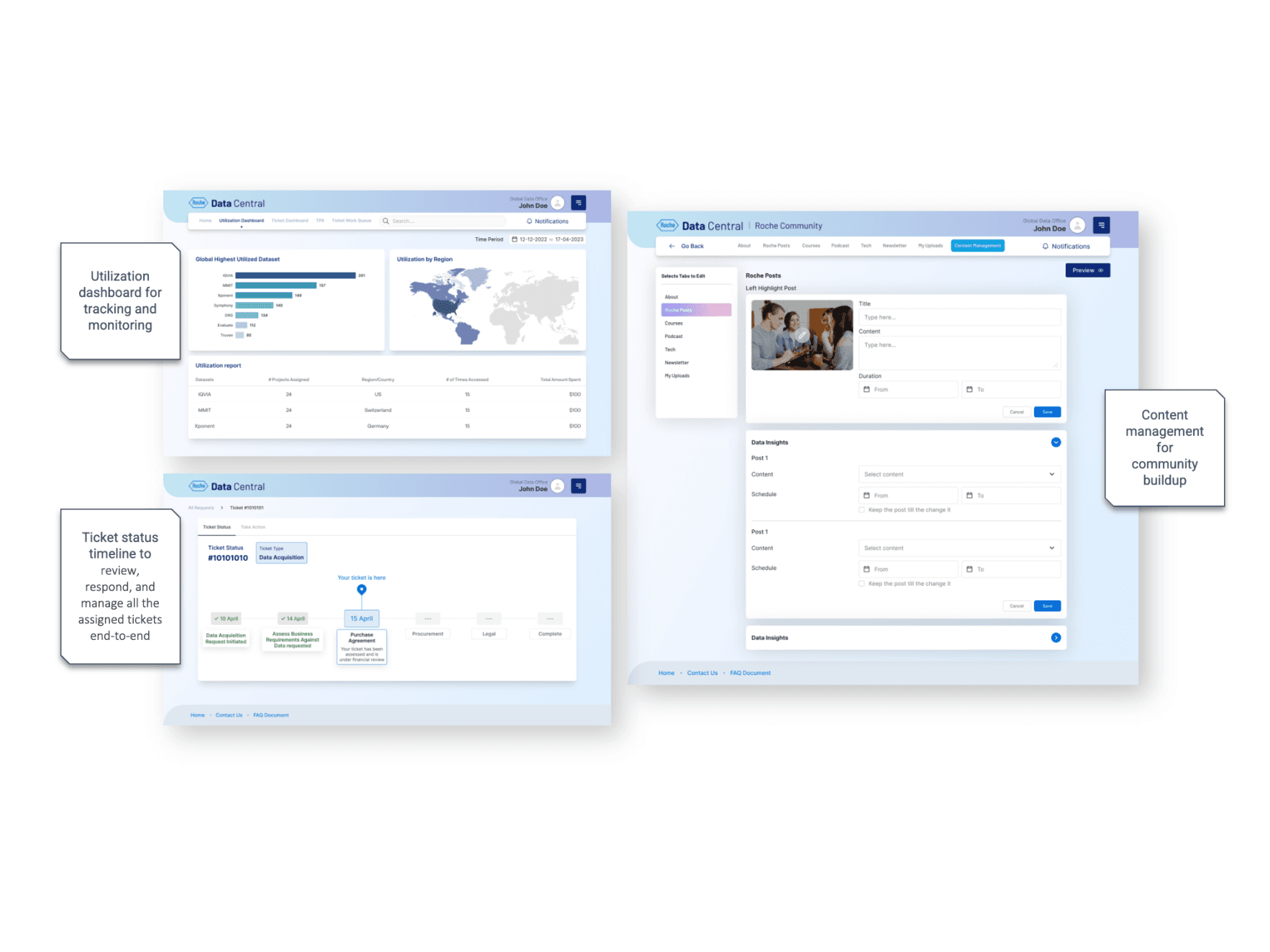
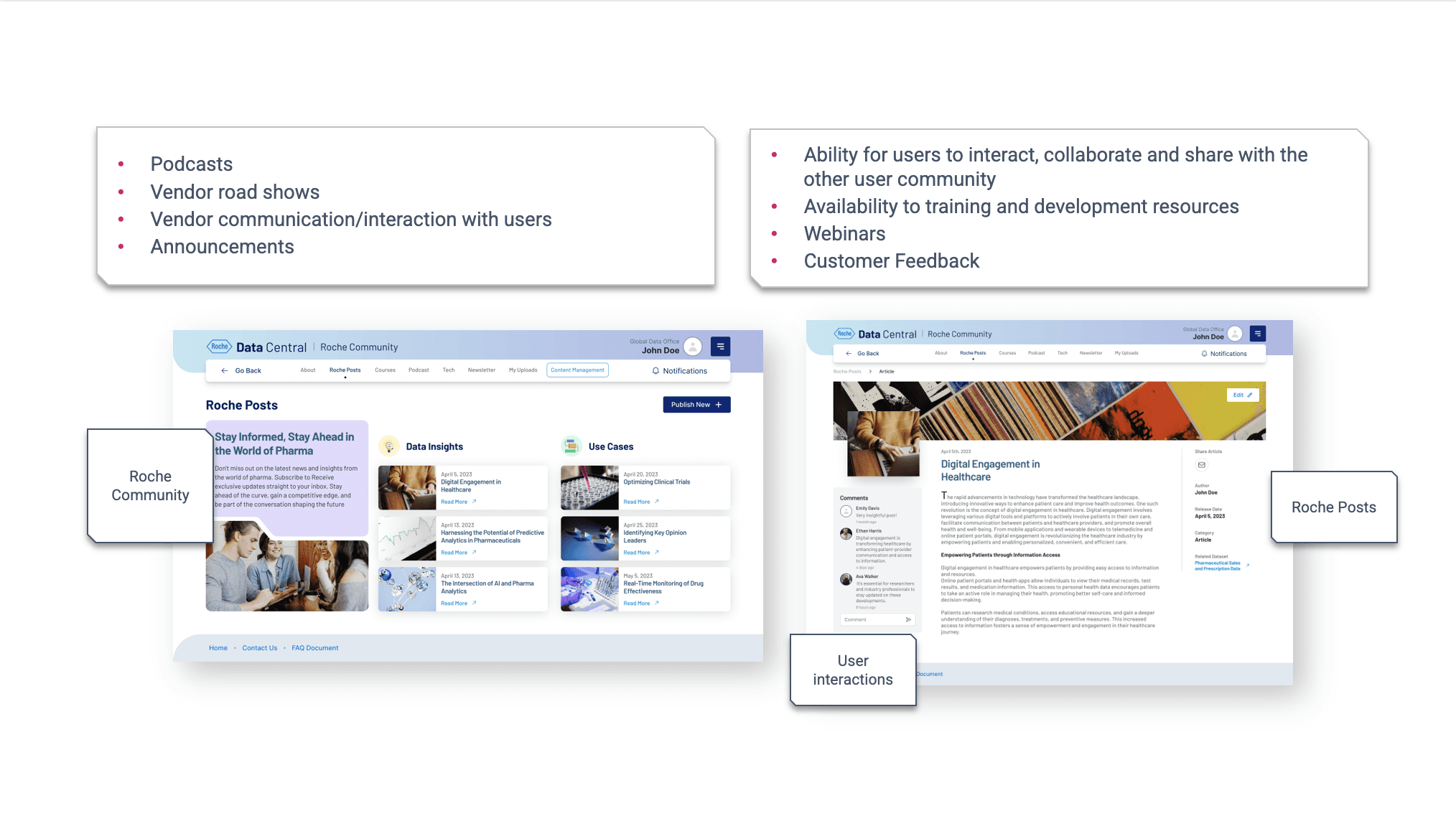
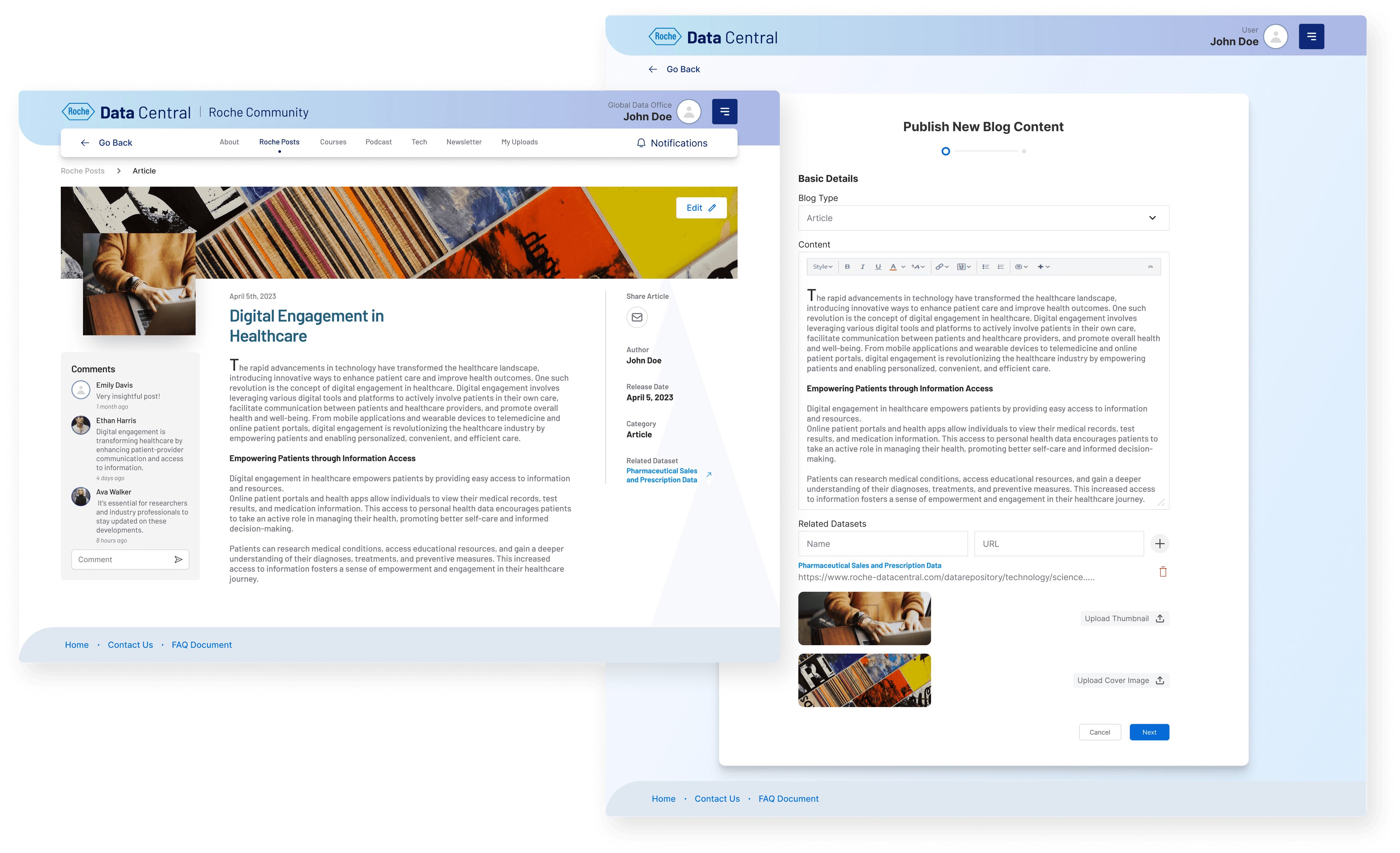
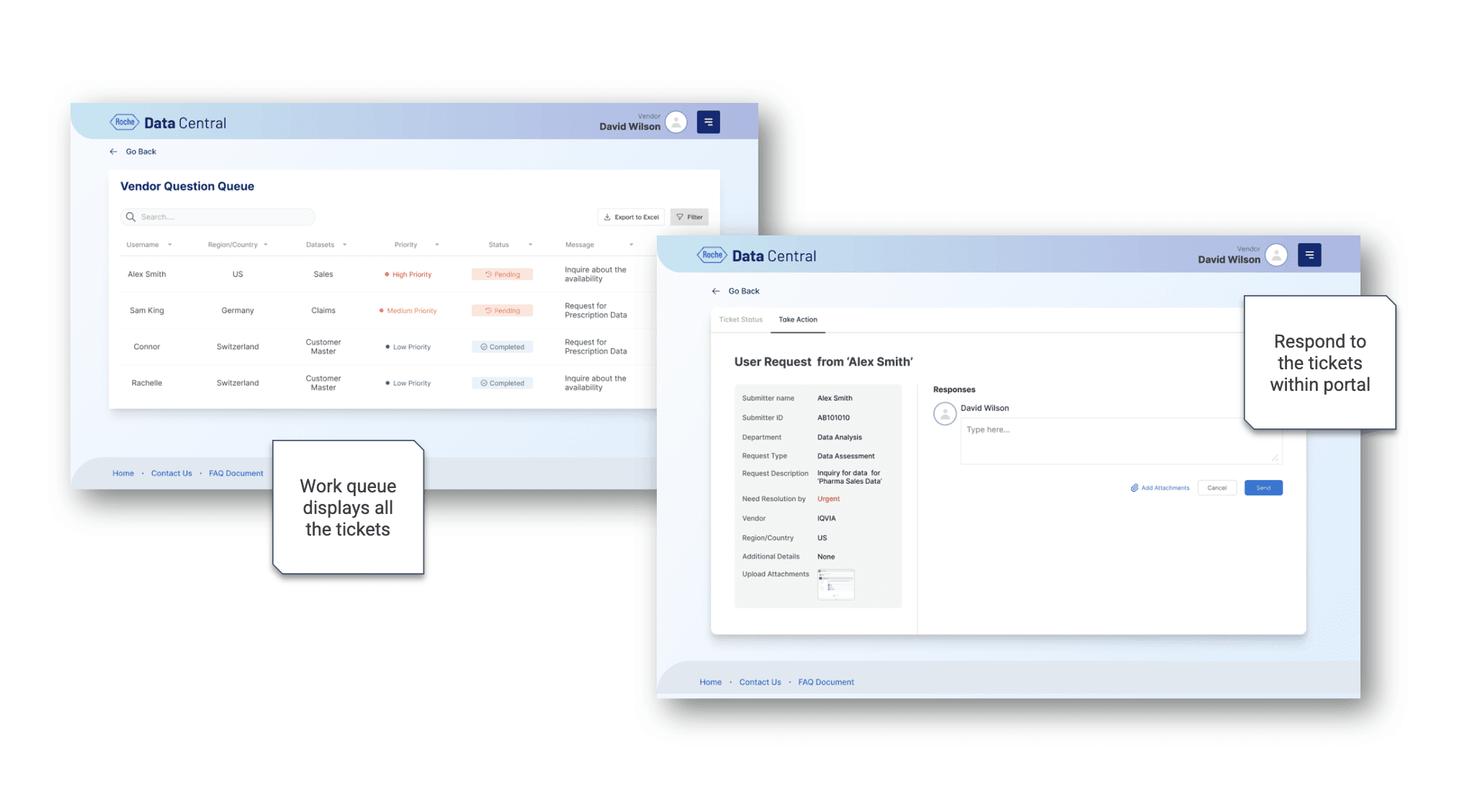
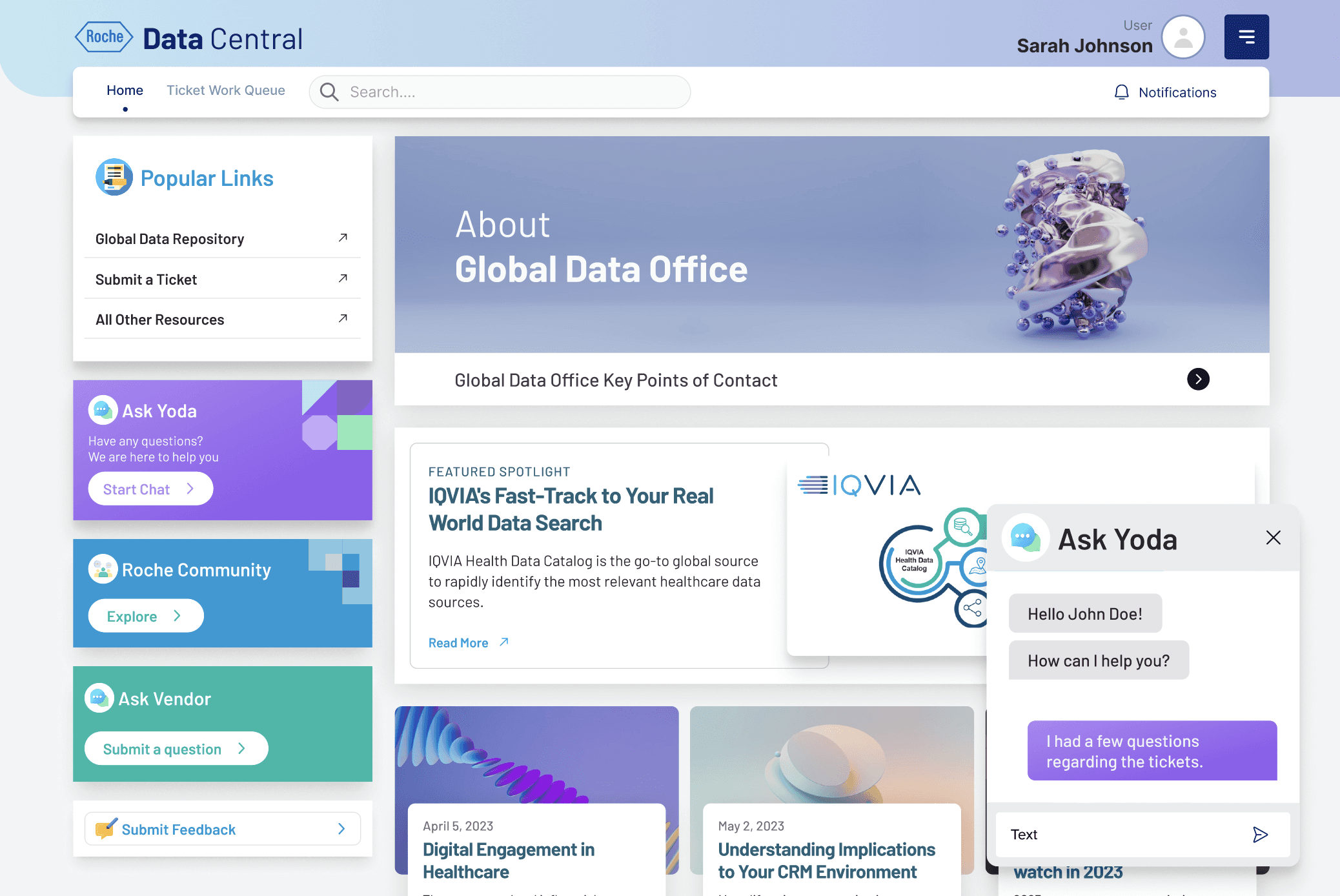
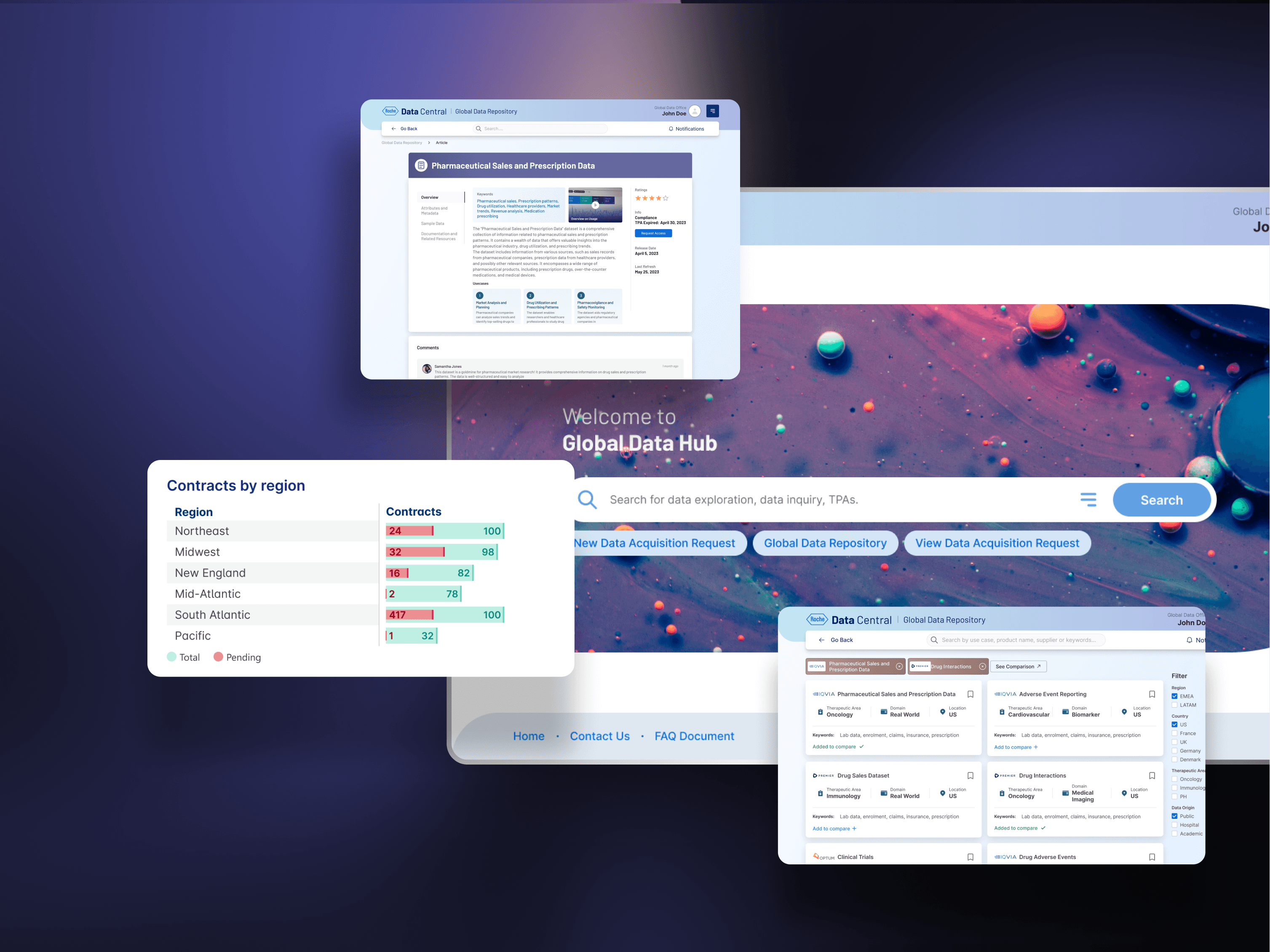
When I joined the Roche Data Office project, teams were drowning in duplicated data purchases and couldn’t even tell if a dataset existed in-house. Millions were being wasted each quarter. That’s when the idea for Data Central was born - a single portal to bring order to the chaos.
I began by interviewing data scientists, procurement managers, and business analysts. Everyone had different frustrations: some couldn’t discover datasets, others struggled with poor metadata, and vendors found it difficult to showcase offerings. Mapping these voices into user journeys gave me a north star - simplicity and transparency.